众所周知的原因搞得安装起来太复杂了,并且helm的prometheus operator的chart项目还迁移过,更有点云里雾里。
创建专用namespace
先创建个namespace来用。
kubectl create namespace monitoring
单独安装CRD
CRD就是Custom Resource Definition。
本来应该是helm install kube-prometheus-stack的时候就能装,but as you know..
通过科学上网,先下载yaml再说:
# 整齐点儿
mkdir -p ~/helm/prometheus-operator
cd ~/helm/prometheus-operator
# 下载yaml
curl -x http://192.168.127.1:58591 -fsSLO https://raw.githubusercontent.com/prometheus-operator/prometheus-operator/master/example/prometheus-operator-crd/monitoring.coreos.com_alertmanagers.yaml
curl -x http://192.168.127.1:58591 -fsSLO https://raw.githubusercontent.com/prometheus-operator/prometheus-operator/master/example/prometheus-operator-crd/monitoring.coreos.com_podmonitors.yaml
curl -x http://192.168.127.1:58591 -fsSLO https://raw.githubusercontent.com/prometheus-operator/prometheus-operator/master/example/prometheus-operator-crd/monitoring.coreos.com_probes.yaml
curl -x http://192.168.127.1:58591 -fsSLO https://raw.githubusercontent.com/prometheus-operator/prometheus-operator/master/example/prometheus-operator-crd/monitoring.coreos.com_prometheuses.yaml
curl -x http://192.168.127.1:58591 -fsSLO https://raw.githubusercontent.com/prometheus-operator/prometheus-operator/master/example/prometheus-operator-crd/monitoring.coreos.com_prometheusrules.yaml
curl -x http://192.168.127.1:58591 -fsSLO https://raw.githubusercontent.com/prometheus-operator/prometheus-operator/master/example/prometheus-operator-crd/monitoring.coreos.com_servicemonitors.yaml
curl -x http://192.168.127.1:58591 -fsSLO https://raw.githubusercontent.com/prometheus-operator/prometheus-operator/master/example/prometheus-operator-crd/monitoring.coreos.com_thanosrulers.yaml
# 安装
kubectl apply -f .
安装 kube-prometheus-stack
kube-prometheus-stack基于prometheus-operator制作,并集成了依赖
- stable/kube-state-metrics
- stable/prometheus-node-exporter
- grafana/grafana
# 安装
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --set prometheusOperator.createCustomResource=false -n monitoring
# 查看安装情况
kubectl -n monitoring get deployments
NAME READY UP-TO-DATE AVAILABLE AGE
kube-prometheus-stack-grafana 1/1 1 1 4h30m
kube-prometheus-stack-kube-state-metrics 1/1 1 1 4h30m
kube-prometheus-stack-operator 1/1 1 1 4h30m
kubectl -n monitoring get pods -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
alertmanager-kube-prometheus-stack-alertmanager-0 2/2 Running 2 4h14m 10.244.1.32 mini-ubuntu <none> <none>
kube-prometheus-stack-grafana-8b85d667c-5w8sn 2/2 Running 4 4h32m 10.244.2.23 mini-centos <none> <none>
kube-prometheus-stack-kube-state-metrics-5cf575d8f8-6m7jt 1/1 Running 1 4h32m 10.244.1.33 mini-ubuntu <none> <none>
kube-prometheus-stack-operator-65fbd96bdb-9zhmz 2/2 Running 6 4h32m 10.244.2.21 mini-centos <none> <none>
kube-prometheus-stack-prometheus-node-exporter-68sxv 1/1 Running 2 4h32m 192.168.127.133 mini-centos <none> <none>
kube-prometheus-stack-prometheus-node-exporter-864w9 1/1 Running 1 4h32m 192.168.127.132 ubuntuserver <none> <none>
kube-prometheus-stack-prometheus-node-exporter-nr274 1/1 Running 1 4h32m 192.168.127.134 mini-ubuntu <none> <none>
prometheus-kube-prometheus-stack-prometheus-0 3/3 Running 6 4h14m 10.244.2.22 mini-centos <none> <none>
遇到问题往后看。
安装过程的Troubleshooting
安装过程各种报错,当然主要是镜像pull不下来,尤其是quay.io的镜像。(我的挺奇怪,居然自己pull成功了几个quay.io)
排查问题
kubectl -n monitoring describe pods prometheus-kube-prometheus-stack-prometheus-0
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Pulling 60m (x4 over 83m) kubelet, mini-centos Pulling image "quay.io/coreos/prometheus-config-reloader:v0.38.1"
Warning Failed 58m (x4 over 79m) kubelet, mini-centos Failed to pull image "quay.io/coreos/prometheus-config-reloader:v0.38.1": rpc error: code = Unknown desc = context canceled
Warning Failed 58m (x4 over 79m) kubelet, mini-centos Error: ErrImagePull
Normal Pulling 58m (x5 over 100m) kubelet, mini-centos Pulling image "quay.io/prometheus/prometheus:v2.18.2"
Normal Pulled 47m kubelet, mini-centos Successfully pulled image "quay.io/coreos/prometheus-config-reloader:v0.38.1" in 1m11.597994512s
Warning Failed 22m (x11 over 83m) kubelet, mini-centos Error: ErrImagePull
Normal BackOff 13m (x130 over 56m) kubelet, mini-centos Back-off pulling image "quay.io/prometheus/prometheus:v2.18.2"
Warning Failed 8m15s (x145 over 56m) kubelet, mini-centos Error: ImagePullBackOff
Warning Failed 3m13s (x14 over 83m) kubelet, mini-centos Failed to pull image "quay.io/prometheus/prometheus:v2.18.2": rpc error: code = Unknown desc = context canceled
解决
google prometheus v2.18.2居然发现docker hub里有,于是在mini-centos主机上:
docker pull prom/prometheus:v2.18.2
v2.18.2: Pulling from prom/prometheus
0f8c40e1270f: Already exists
626a2a3fee8c: Already exists
dde61fbb486b: Already exists
22b936665674: Downloading [=================================================> ] 20.66MB/20.76MB
b9cb37b79bc0: Download complete
a14008f52cd5: Download complete
c89901a55493: Waiting
就定这儿了,遂祭起重启docker大法:
sudo systemctl restart docker
重启完后,接着:
docker pull prom/prometheus:v2.18.2
v2.18.2: Pulling from prom/prometheus
0f8c40e1270f: Already exists
626a2a3fee8c: Already exists
dde61fbb486b: Already exists
22b936665674: Pull complete
b9cb37b79bc0: Pull complete
a14008f52cd5: Pull complete
c89901a55493: Pull complete
6caddd047c54: Pull complete
ddd1779460e5: Pull complete
f65cc1a7f25d: Pull complete
4be7bc9429a7: Pull complete
2d296d78b122: Pull complete
Digest: sha256:4d3303d1eb424e345cf48969bb7575d4d58472ad783ac41ea07fba92686f7ef5
Status: Downloaded newer image for prom/prometheus:v2.18.2
docker.io/prom/prometheus:v2.18.2
再检查:
kubectl -n monitoring get pods -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
alertmanager-kube-prometheus-stack-alertmanager-0 2/2 Running 2 4h14m 10.244.1.32 mini-ubuntu <none> <none>
kube-prometheus-stack-grafana-8b85d667c-5w8sn 2/2 Running 4 4h32m 10.244.2.23 mini-centos <none> <none>
kube-prometheus-stack-kube-state-metrics-5cf575d8f8-6m7jt 1/1 Running 1 4h32m 10.244.1.33 mini-ubuntu <none> <none>
kube-prometheus-stack-operator-65fbd96bdb-9zhmz 2/2 Running 6 4h32m 10.244.2.21 mini-centos <none> <none>
kube-prometheus-stack-prometheus-node-exporter-68sxv 1/1 Running 2 4h32m 192.168.127.133 mini-centos <none> <none>
kube-prometheus-stack-prometheus-node-exporter-864w9 1/1 Running 1 4h32m 192.168.127.132 ubuntuserver <none> <none>
kube-prometheus-stack-prometheus-node-exporter-nr274 1/1 Running 1 4h32m 192.168.127.134 mini-ubuntu <none> <none>
prometheus-kube-prometheus-stack-prometheus-0 3/3 Running 6 4h14m 10.244.2.22 mini-centos <none> <none>
全都ready了。
如有其他pull问题,应该可以如法炮制。
暴露服务
查看服务
kubectl -n monitoring get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 4h16m
kube-prometheus-stack-alertmanager ClusterIP 10.101.245.140 <none> 9093/TCP 4h34m
kube-prometheus-stack-grafana ClusterIP 10.106.193.98 <none> 80/TCP 4h34m
kube-prometheus-stack-kube-state-metrics ClusterIP 10.108.208.70 <none> 8080/TCP 4h34m
kube-prometheus-stack-operator ClusterIP 10.110.217.187 <none> 8080/TCP,443/TCP 4h34m
kube-prometheus-stack-prometheus ClusterIP 10.104.189.224 <none> 9090/TCP 4h34m
kube-prometheus-stack-prometheus-node-exporter ClusterIP 10.102.189.12 <none> 9100/TCP 4h34m
prometheus-operated ClusterIP None <none> 9090/TCP 4h16m
改NodePort
把下面服务的type改成NodePort:
kubectl -n monitoring edit svc kube-prometheus-stack-prometheus
kubectl -n monitoring edit svc kube-prometheus-stack-alertmanager
kubectl -n monitoring edit svc kube-prometheus-stack-grafana
kubectl -n monitoring get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 4h51m
kube-prometheus-stack-alertmanager NodePort 10.101.245.140 <none> 9093:31386/TCP 5h9m
kube-prometheus-stack-grafana NodePort 10.106.193.98 <none> 80:30835/TCP 5h9m
kube-prometheus-stack-kube-state-metrics ClusterIP 10.108.208.70 <none> 8080/TCP 5h9m
kube-prometheus-stack-operator ClusterIP 10.110.217.187 <none> 8080/TCP,443/TCP 5h9m
kube-prometheus-stack-prometheus NodePort 10.104.189.224 <none> 9090:30098/TCP 5h9m
kube-prometheus-stack-prometheus-node-exporter ClusterIP 10.102.189.12 <none> 9100/TCP 5h9m
prometheus-operated ClusterIP None <none> 9090/TCP 4h51m
访问prometheus
打开http://192.168.127.132:30098/targets,一部分up一部分down,点Unhealthy
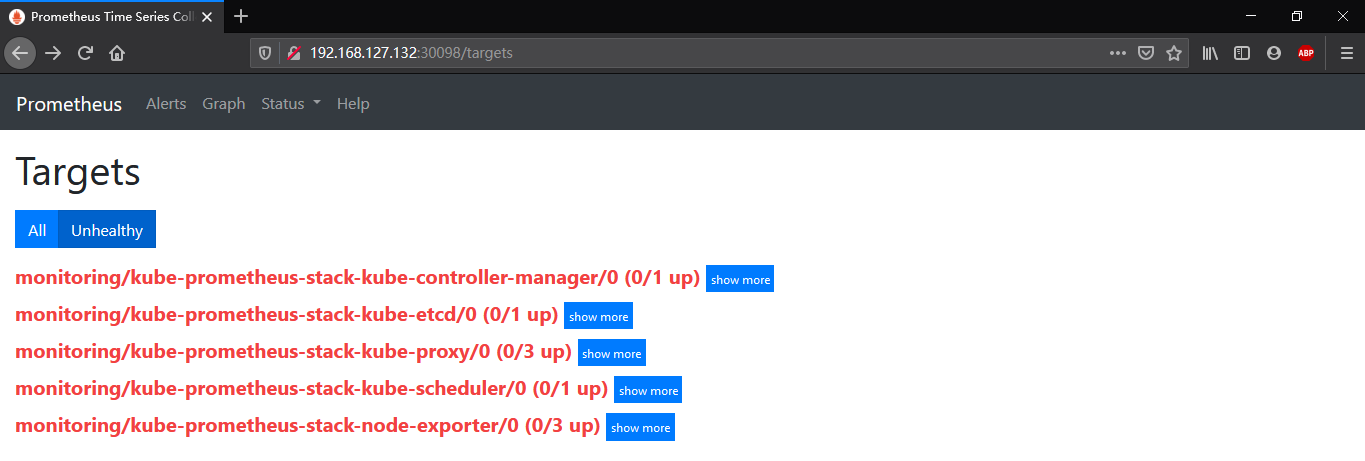
解决down的部分
etcd的down
搞了1.5天,搜到的各种资料都无法适用,结合各家之言,再无数次尝试才勉强有结果。
sudo vim /etc/kubernetes/manifests/etcd.yaml
# 找到
- --listen-client-urls=https://127.0.0.1:2379,https://192.168.127.132:2379
# 修改为
- --listen-client-urls=https://0.0.0.0:2379,http://0.0.0.0:2379
# 重启全部container(实际上是停止命令,k8s会自动全部启动)
docker stop $(docker ps -q)
挺奇葩的一点是,down变为up后,我又改回原配置,再重启全部container,依然保持up状态,存疑ing。
kube-scheduler的down
sudo vim /etc/kubernetes/manifests/kube-scheduler.yaml
//改为- --bind-address=0.0.0.0
//删行- --port=0
//稍等几秒即可
这个要特别感谢度娘帮我搜到的解决kubernetes:v1.18.6-1.19.0 get cs127.0.0.1 connection refused错误。一个port你说你默认等于0干啥,你自己都unhealthy你说prometheus哪儿能监控得到。感谢原作者,n个小时后终于破案。
kube-controller-manager的down
修改套路同kube-scheduler。
sudo vim /etc/kubernetes/manifests/kube-controller-manager.yaml
//改为- --bind-address=0.0.0.0
//删行- --port=0
//稍等几秒即可
node-exporter的down
kubectl -n monitoring edit ds kube-prometheus-stack-prometheus-node-exporter
//删掉 hostNetwork: true 一行
//稍等几秒即可
//还没尝试helm给参数的方式,有机会试试override the hostNetwork setting using a values file with -f option
特别感谢google来的Fix Context Deadline Exceeded Error in Prometheus Operator
kube-proxy的down(尚未搞定)
暂时跳过,快崩溃了(人),下面的方法用了根本不行,google bing baidu齐上阵,前前后后得搞了1天。好心的哪位,可否帮忙留言个正解?
# 可能用得到的指令
kubectl -n kube-system edit cm kube-proxy //改metricsBindAddress: 为 0.0.0.0:10249
kubectl delete pod -l k8s-app=kube-proxy -n kube-system
// 按上面的操作,完全没效果,晕
sudo netstat -ntlp | grep kube
sudo ss -ntlp | grep kube
这是第一个开始搞的,结果其他都搞定了,它还岿然不动。
Grafana篇章
kube-prometheus-stack里已经自带Grafana,因此无需安装。
访问grafana
kubectl -n monitoring get svc //找到grafana的端口,然后浏览器访问http://IP:PORT
用户名/密码是?
一堆说admin/admin的,然而这个环境不适用。
用户名:admin
密码:prom-operator
特别感谢Deploy Prometheus Operator with Helm3 and Private Registry
漂亮
在Manage里随便选一个
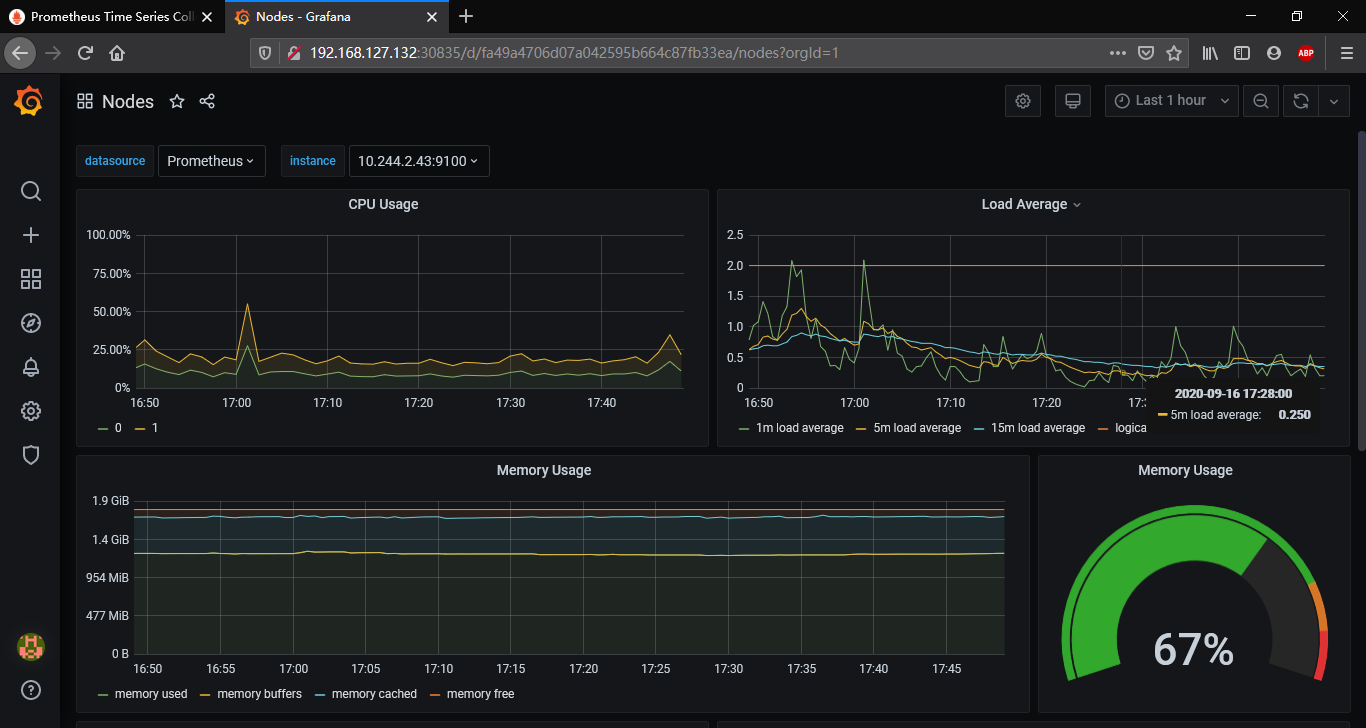
日志篇章EFK
Elasticsearch+Fluentd+Kibana
大部分参考一文彻底搞定 EFK 日志收集。
几处调整
elasticsearch-statefulset.yaml
# 执行之前,给nodes打es=log标签
kubectl label nodes --all es=log
# 修改containers的image,因为docker.elastic.co的慢,pull容易失败
image: elasticsearch:7.9.1
# 因为是测试,没有rook ceph,因此就替换volumn为emptydir
# volumeClaimTemplates: 段落改为了:
volumes:
- name: data
emptyDir: {}
用kubectl -n logging get pods观察,发现statefulset的pod是one by one搞的。部署过程不快,看了下,elasticsearch的镜像700多MB。
参考链接:
https://github.com/prometheus-community/helm-charts/tree/main/charts/kube-prometheus-stack
https://github.com/prometheus-operator/prometheus-operator
https://github.com/prometheus-operator/kube-prometheus
https://www.bookstack.cn/read/kubernetes-learning-0.2.0/docs-58.Prometheus%20Operator.md
https://www.qikqiak.com/post/prometheus-operator-monitor-etcd/
https://blog.fleeto.us/post/node-downtime/
解决kubernetes:v1.18.6-1.19.0 get cs127.0.0.1 connection refused错误
Fix Context Deadline Exceeded Error in Prometheus Operator
Deploy Prometheus Operator with Helm3 and Private Registry
一文彻底搞定 EFK 日志收集
稍后阅读:
Kubernetes HPA 使用详解
Kubernetes运维之使用Prometheus全方位监控K8S
Linux操作系统load average过高,kworker占用较多cpu