本文主要是踩坑后想记录下避坑方法,内容涉及Kubernetes, Kubeadm, Kubectl, Kubelet, Ubuntu, CentOS, Flannel, Docker, 阿里云。
写作背景
初学Kubernetes,虽然网上资源很多,但没一个能彻底搞定,于是杂烩一下。
安装前的准备工作
control node(控制节点)、worker node(工作节点) 都要做这些准备工作。
检查各主机配置
检查cpu和内存
无论是虚拟机还是物理机,都要求cpu内核≥2,内存≥2G。
检查主机名hostname
hostname要求不能是 localhost,且不包含下划线、小数点、大写字母。
# 检查hostname
hostname
# 修改 hostname
hostnamectl set-hostname 名字
# 查看修改结果
hostnamectl status
# 设置 hostname 解析
echo "127.0.0.1 $(hostname)" >> /etc/hosts
设置固定IP
建议使用nmcli配置,因为跨平台(Ubuntu和CentOS)。
nmcli
//如果提示没有安装,先按下面步骤安装
# 安装nmcli
sudo yum install NetworkManager #CentOS
sudo apt-get install network-manager #Ubuntu
# 检查nmcli是否接管了网络管理
nmcli g
//正常是显示绿色的信息。如果STATE列显示disconnected,则Ubuntu要修改/etc/netplan/里的yaml文件,在version下面添加一行renderer: NetworkManager,保存退出后执行sudo systemctl daemon-reload 和 sudo systemctl restart NetworkManager
# 查看当前默认网卡和ip信息
ip route show
ip a
//ip route show 命令中,可以知道机器的网关DNS和默认网卡,如 default via 192.168.127.2 dev ens33,via后面的内容 192.168.127.2 就是网关和DNS,dev后面的内容 ens33 就是默认网卡
//ip a 命令中,可显示默认网卡的 IP 地址,Kubernetes 将使用此 IP 地址与集群内的其他节点通信,如192.168.127.131
//所有节点上 Kubernetes 所使用的 IP 地址必须可以互通(无需 NAT 映射、无安全组或防火墙隔离)
# 设置固定IP,网卡、ip地址、网关、DNS可参考上面的信息
sudo nmcli c mod ens33 \
ipv4.addresses 192.168.127.131/24 \
ipv4.method manual \
ipv4.gateway 192.168.127.2 \
ipv4.dns 192.168.127.2
# 让配置立刻生效
sudo nmcli c up ens33
设置iptables
执行下面代码:
sudo modprobe br_netfilter
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sudo sysctl --system
# 如果想检查配置,可执行
sysctl -n net.bridge.bridge-nf-call-iptables
sysctl -n net.bridge.bridge-nf-call-ip6tables
打开端口
Ubuntu的准备工作
先打开Ubuntu自带的防火墙ufw。执行下面代码:
sudo ufw enable
执行后提示可能断开连接,直接y继续,别担心,ssh连接不会断。
如果使用ssh连接,还需要执行下面代码,以便打开ssh连接:
sudo ufw allow ssh
打开相应端口
依据所使用的系统(Ubuntu / CentOS),执行相应代码。
- 控制节点 Control-plane nodes
# Ubuntu
sudo ufw allow 6443/tcp
sudo ufw allow 2379:2380/tcp
sudo ufw allow 10250:10252/tcp
sudo ufw allow 8472/udp #for flannel。如果不开,则coredns无法为worker nodes服务
//上面代码中的冒号代表端口区间。
# CentOS
sudo firewall-cmd --zone=public --add-port=6443/tcp --permanent
sudo firewall-cmd --zone=public --add-port=2379-2380/tcp --permanent
sudo firewall-cmd --zone=public --add-port=10250-10252/tcp --permanent
sudo firewall-cmd --zone=public --add-port=8472/udp --permanent #for flannel。如果不开,则coredns无法为worker nodes服务
sudo firewall-cmd --add-masquerade --permanent #for flannel NAT
sudo firewall-cmd --reload
sudo firewall-cmd --list-ports //查看设置效果
- 工作节点 Worker nodes
# Ubuntu
sudo ufw allow 10250/tcp
sudo ufw allow 30000:32767/tcp
sudo ufw allow 8472/udp #for flannel
# CentOS
sudo firewall-cmd --zone=public --add-port=10250/tcp --permanent
sudo firewall-cmd --zone=public --add-port=30000-32767/tcp --permanent
sudo firewall-cmd --zone=public --add-port=8472/udp --permanent #for flannel
sudo firewall-cmd --add-masquerade --permanent #for flannel NAT
sudo firewall-cmd --reload
sudo firewall-cmd --list-ports //查看设置效果
禁用swap
由于swap性能低下,Kubeadm默认要求禁止使用swap。执行如下代码:
sudo swapoff -a #临时禁用swap
sudo sed -i 's/.*swap.*/#&/' /etc/fstab #永久禁用swap
# Fedora 33 使用了zram swap
cat /proc/swaps #显示为/dev/zram0
sudo systemctl stop swap-create@zram0
sudo swapoff -a #临时禁用
sudo touch /etc/systemd/zram-generator.conf #永久禁用
可通过free -m来检查禁用效果。
安装docker
创建k8s文件夹
可用来存放相关文件。执行下面代码:
mkdir ~/k8s
安装kubeadm, kubelet和kubectl
control node(控制节点)、worker node(工作节点) 上都安装。
Ubuntu
sudo apt-get update && sudo apt-get install -y apt-transport-https curl
curl -s https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | sudo apt-key add -
cat <<EOF | sudo tee /etc/apt/sources.list.d/kubernetes.list
deb https://mirrors.aliyun.com/kubernetes/apt kubernetes-xenial main
EOF
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
sudo apt-mark hold kubelet kubeadm kubectl
CentOS
cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
exclude=kubelet kubeadm kubectl
EOF
# Set SELinux in permissive mode (effectively disabling it)
sudo setenforce 0
sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
sudo yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes
sudo systemctl enable --now kubelet
在control node控制节点上用kubeadm创建集群
初始化集群
sudo kubeadm init --image-repository=registry.cn-hangzhou.aliyuncs.com/google_containers \
--pod-network-cidr=10.244.0.0/16 \
# 以下是输出的内容
kubeadm join 192.168.127.132:6443 --token 4pwz11.1m0u1k3ak3ibgx08 \
--discovery-token-ca-cert-hash sha256:671404c4f80afe5d06d8eefcd5acc6049c4d84f1ebf1091b09bc180ea44e79b7
将输出内容中的kubeadm join ...记录下来,这是其他节点加入主节点的信息。
赋予当前用户使用kubectl的权限
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
安装网络组件flannel
准备工作
由于种种原因,无法直接pull到网络组件flannel的docker镜像,因此需单独下载。
https://github.com/coreos/flannel/releases/download/v0.12.0/flanneld-v0.12.0-amd64.docker
下载后放进~/k8s,执行命令:
cd ~/k8s
docker load < flanneld-v0.12.0-amd64.docker
开始安装
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
kubectl apply -f kube-flannel.yml
检查部署情况
kubectl get nodes

kubectl get pods -A
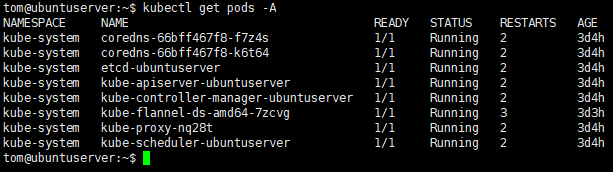
通过docker container ls也可以看到pods里的容器运行情况。
打开kubectl和kubeadm的自动补全功能
echo 'source <(kubectl completion bash)' >>~/.bashrc
echo 'source <(kubeadm completion bash)' >>~/.bashrc
source ~/.bashrc #使配置立刻生效
以上为control node控制节点的部署全流程。
worker node工作节点加入集群
确认在worker node主机上已安装了kubeadm, kubelet和kubectl。
如未安装,参考安装kubeadm, kubelet和kubectl。
安装网络组件flannel
- 在control node上导出flannel的docker镜像,并复制到worker node:
提醒:~/k8s目录在各node上都提前建好
docker save quay.io/coreos/flannel:v0.12.0 > ~/k8s/flannel-v0.12.0.tar
scp ~k8s/flannel-v0.12.0.tar tom@192.168.127.133:~/k8s
- 在worker node上导入flannel的docker镜像:
docker load < k8s/flannel-v0.12.0.tar
加入集群
在worker node上,执行之前记录的kubeadm join...代码,类似于:
sudo kubeadm join 192.168.127.132:6443 --token rddtz5.mz2v4ee96177eay5 --discovery-token-ca-cert-hash sha256:671404c4f80afe5d06d8eefcd5acc6049c4d84f1ebf1091b09bc180ea44e79b7
如果join指令没记录下来,或者集群创建已经超过24小时了,那么需要重新生成join指令。在control node上执行:
kubeadm token create --print-join-command
复制输出的内容并在worker node上执行即可加入。
检查部署结果
在control node上执行:
kubectl get nodes -o wide

kubectl get pods -A -o wide

如果STATUS不是Running,则排查故障点:
kubectl describe pods -n kube-system kube-proxy-t2zbw
Troubleshooting
pull image失败
如果kubectl get pods -n kube-system -o wide发现某个pods还没ready,而docker也已经配置了国内加速器,那么试着重启docker一下。
sudo systemctl restart docker.service
参考链接:
https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/install-kubeadm/
https://www.cnblogs.com/hellxz/p/use-kubeadm-init-kubernetes-cluster.html
https://www.kuboard.cn/install/install-k8s.html
https://blog.csdn.net/LeonardoYasuo/article/details/101483438
https://www.cnblogs.com/yinzhengjie/p/12258215.html
https://developer.aliyun.com/article/763983
https://fedoraproject.org/wiki/Changes/SwapOnZRAM